
Nel mondo digitale di oggi, essere visibili online non è più un’opzione ma una necessità. Il posizionamento del sito web gioca un ruolo cruciale in questo, determinando quanto facilmente il tuo sito possa essere trovato dai potenziali clienti sui motori di ricerca. Ma che cos’è esattamente il posizionamento di un sito web e come funziona? […]

Continuando il discorso intrapreso sulla SEO Semantica, oggi proverò a fare un esempio ed a inviare ai motori di ricerca Dati e non Parole da Interpretare grazie all’uso del linguaggio HTML5 ed allo schema di markup standard al quale Google, Yahoo, Bing e Yandex hanno dato il loro ok; appunto Schema.org
Chiaramente oggi il mio lato Seo Tecnico che tanto mi contraddistingue dai Seo Copy prenderà il sopravvento. 😀
Innanzitutto mi piace definire l’ HTML5 come un vero salto di qualità rispetto al XHTML2 che permette di identificare informazioni grazie a TAG o MARCATORI SPECIFICI creati appositamente, e non grazie a DIV GENERICI che il motore deve interpretare visitandone il contenuto. Un linguaggio ampliato che raccogliere tantissimi nuovi elementi, e che migliora davvero l’integrazione con i dispositivi mobile grazie ad una maggior integrazione delle API Java; che puo’ essere plasmato in base alle proprie necessità di strutturazione di contenuti / dati.
Esempi lampanti sono l’introduzione di tantissimi nuovi marcatori i cui significati parlano da soli. Non potendo scrivere in quattro righe tutte le novià introdotte, analizzerò solo quelle che oggi sono utili alla causa di questo post:
- HEADER (Parte Iniziale)
- ARTICLE (articolo)
- FOOTER (Parte Finale)
- TIME (Data o Tempo)
Non parlero’ di come, dove, o quando implementare questi nuovi Marcatori (potete trovare tutto qui ), ma proverò a far vedere che questi possono effettivamente avere un significato e come poi integrarli con Schema.org.
Facciamo il classico esempio di un articolo di un blog:
Senza considerare l’intera pagina e tutto il codice di contorno che necessita di scrivere in HTML5 (a cominciare dalla dichiarazione del DOCTYPE), possiamo affermare in linea di massima che prima eravamo abituati a definire un DIV contenitore all’interno del quale piazzare il titolo e la descrizione del notro articolo per poi partire con il contenuto vero e proprio. Io ho sempre fatto così:
<div>
<h1>Titolo Articolo</h1>
<h2>Descrizione</h2>
<p>Contenuto</p>
<p>scritto da Alessandro Romano Seo il 4 settembre 2014</p>
</div>
ma oggi?
Convertire XHTML in HTML5
Oggi invece è possibile innanzitutto dire ai motori, nel momento in cui lo spider sta analizzando la pagina, che, quando arriva sul nostro contenuto principale (articolo), si trova effettivamente sulla parte di codice che lo definisce. Come? cosi:
<article>
<header>
<h1>Titolo Articolo</h1>
<h2>Descrizione</h2>
</header>
<p>Contenuto articolo</p>
<footer>
<p>scritto da Alessandro Romano Seo il <time pubdate datetime=”2014-09-04”>4 settembre 2014</time></p>
</footer>
</article>
Analizziamo il valore di questi nuovi elementi senza approfondire troppo in quanto ci vorrebbero decine e decine di post per spiegare quali e quante sono le modalità d’uso di ognuno di questi nuovi marcatori:
Article:
il tag article può identificare il post di un forum, un articolo di una rivista o di un giornale, l’articolo di un blog, un commento, un widget interattivo, o qualsiasi cosa che abbia un contenuto indipendente.
Header:
il tag header serve a rappresentare “un gruppo di ausili introduttivi o di navigazione”.
Footer:
L’elemento footer deve contenere in genere informazioni sulla sezione che lo contiene come: i dati di chi ha scritto i contenuti; collegamenti ai documenti correlati; i dati di copyright; e così via
Time:
l’elemento time rappresenta il tempo su un orologio di 24 ore, o una data precisa nel calendario Gregoriano accompagnata opzionalmente con un orario e una differenza di fuso orario.
Con l’utilizzo di questo markup (HTML5) abbiamo dato un valore semantico al codice della pagina e nello specifico abbiamo detto allo spider che si trova in quella porzione di codice che:
- sta analizzando un articolo
- con titolo (h1)
- e sottotitolo (h2)
- che dice (p)
- che è stato scritto da (p )
- e che è stato pubblicato il (time pubdate datetime).
Vediamo se abbiamo scritto tutto bene rispettando le regole del W3C
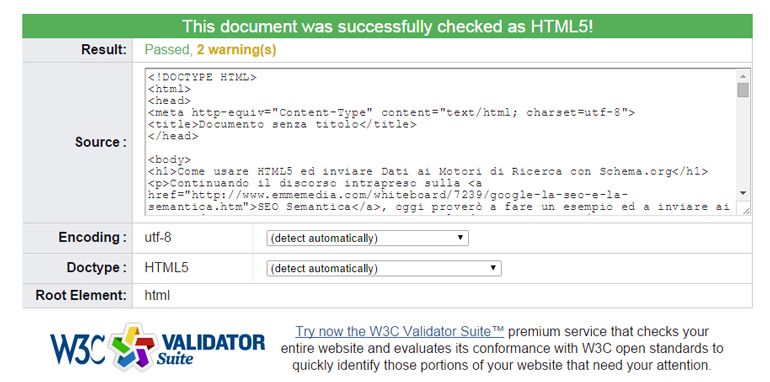
Microdata, Google e Schema.org
Con l’esempio descritto ho cercato di far intuire che, grazie a questi nuovi tag analizzati, la semantica è un punto fondamentale dell’ HTML5.
Ma come possiamo assegnare delle etichette a questi contenuti per descrivere la tipologia di informazione che vogliamo dare?
Ecco che ci vengono in aiuto i Microdata una serie di attributi utilizzabili all’interno degli elementi HTML che permettono di aggiungere significato al documento e la creazione degli oramai famosissimi ed utilissimi Rich Snippet:
<article itemscope itemtype=’http://schema.org/BlogPosting’>
<h1 itemprop=’headline name’>Titolo Articolo</h1>
<h2>Descrizione</h2>
</header>
<div itemprop=’articleBody’>
<p>Contenuto articolo</p>
</div>
<footer>
<p>scritto da <span itemprop=’author’>Alessandro Romano Seo</span> il <time pubdate datetime=’2014-09-04′ itemprop=’datePublished’>4 settembre 2014</time></p>
</footer>
</article>
Anche qui non voglio soffermarmi troppo per descrivere tutte le novità e le varie modalità di implementazione, ma mi limiterò a citare quelli usati nell’esempio (per una guida esaustiva vi rimando a questa pagina):
Itemscope
definisce l’elemento a cui è applicato è un contenitore dell’oggetto che andremo a descrivere.
Itemtype
definisce il vocabolario che specifica il tipo di oggetto che andremo a descrivere.
Itemprop
sugli elementi che discendono dall’elemento radice specifichiamo l’attributo itemprop che definisce la proprietà che verrà valorizzata con il testo contenuto nel tag.
Anche qui possiamo realmente effettuare un test e verificare se abbiamo fatto tutto bene con lo Strumento di test per i dati strutturati di Google
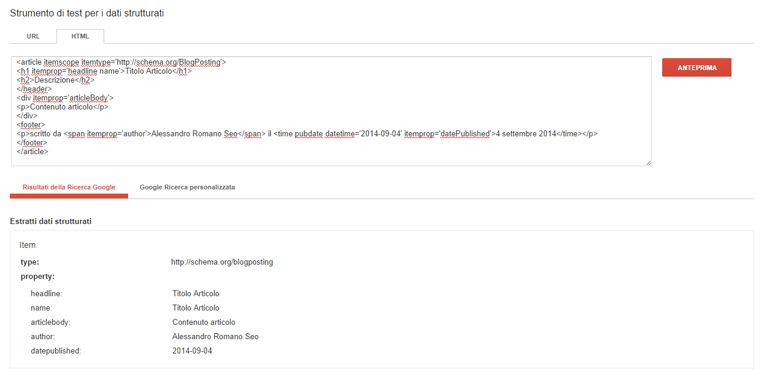
Vorrei specificare che questo esempio puo’ risultare estremamente riduttivo in quanto abbiamo usato un misero post di un blog. Se immaginassimo invece di dover strutturare i dati relativi, ad esempio di una ricetta (magari di un cocktail), possiamo capire che potremmo specificare i singoli ingredienti, il tempo di realizzazione, le quantità, i valori nutrizionali di ognuno ecc …
Attualmente per le ricette, Schema.org prevede la specifica di queste proprietà:
- cookTime (tempo di cottura)
- cookingMethod (metodo di preparazione)
- ingredients (ingredienti)
- nutrition (valori nutrizionali)
- prepTime (tempo per la preparazione)
- recipeCategory (categoria della ricetta)
- recipeCuisine (La cucina della ricetta, ad esempio, francese o etiope)
- recipeInstructions (istruzioni per la preparazione)
- recipeYield (quantità prodotte)
- totalTime (tempo per la realizzazione)
Sperando che questo post abbia aperto un pò la mente a tutti, non rimane altro da fare che approfondire questo splendido mondo ed imparare come sfruttare le potenzialità dell’ HTML5 e come integrare Schema.org all’interno delle nostre pagine Web.
Vuoi essere aggiornato e seguire i nostri articoli? Iscriviti alla newsletter
